1. Quantization이란
- 32-bit floating point 기반 값/연산을 8-bit integer 등의 적은 bit 기반으로 변환하는 것
2. Why
- 이렇게 하면 이것들을 저장할 때 약 75%의 메모리 감소, inference 시 연산에 필요한 자원도 감소 !
- 구체적으로, 캐쉬 사용 효율성 up, RAM 접근에서의 병목 현상 방지, 가용 DSP 칩 더 확보 등
3. How
- 각 layer의 min, max 값을 저장하고 각각의 소수 값을 정해진 일정 범위 안에서 가장 가까운 실수로 mapping해서 2^8 (=256) 개의 8-bit integer로 나타냄
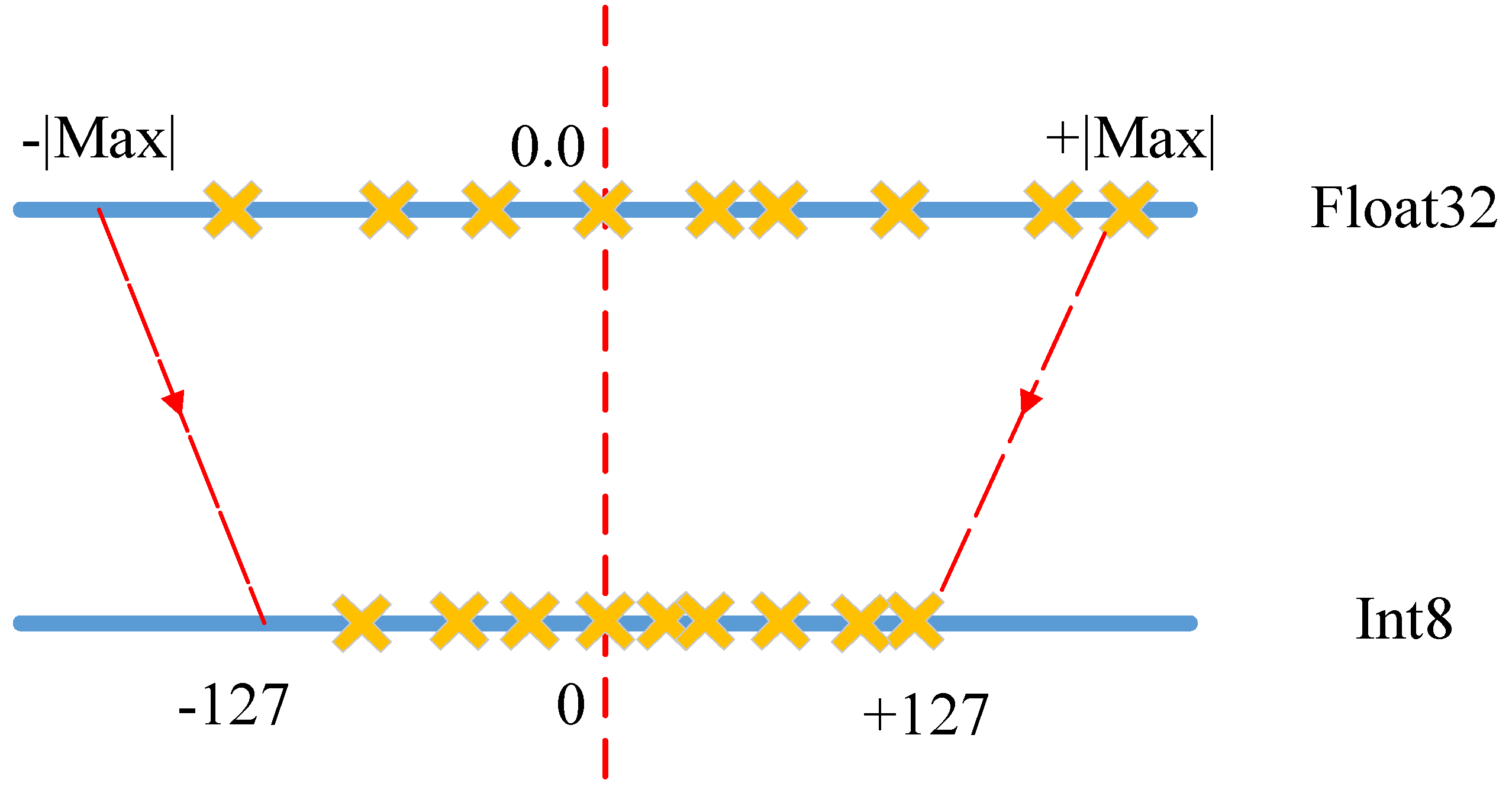
- 일정 범위라는 것은 int8, uint8, int32, int16, uint16 등 뭔지에 따라 다르게 정해지는 것 같음
4. 종류
1) Dynamic quantization
- training 후 모델 weight들을 quantization하고
- activation에 대해서는 부동 소수점 형태로 저장해놨다가 inference할때 quantize하고 완료후 다시 dequantize해서 저장
2) Static quantization
- weight와 activation 모두 사전 양자화
- context-switching overhead 줄이기 위해 activation과 그전 layer를 합치는 fusion 수행
3) Quantization-aware training
- training 시 fake quantization module을 두어서 중간 중간 simulation을 할 수 있고
- fake quantization module은 clamping, rounding 수행
- training 완료 시 모듈에 저장된 scale, zero poinr 등의 값들로 int8로 모델 변환 가능
- 다른 방법보다 accuracy 더 잘나옴
참고자료
텐서플로우에서의 양자화 (Quantize) 시키는 방법
[이글은 https://www.tensorflow.org/performance/quantization 의 내용을 한글로 번역/의역한 내용입니다. 주관적 의견이 첨가되었으니 잘못된 해석이 있다면 지적하여 주시면 감사하겠습니다.] 뉴럴넷 이 처
itteckmania.blogspot.com
'가슴으로 이해하는 > 경량화, Quantization' 카테고리의 다른 글
| [논문 리뷰] GhostSR: Learning Ghost Features for Efficient Image Super-Resolution (0) | 2021.11.30 |
|---|---|
| [논문 리뷰] Once-for-all: Train One Network and Specialize It for Efficient Deployment (2) | 2021.09.07 |

