https://arxiv.org/abs/2101.08525
GhostSR: Learning Ghost Features for Efficient Image Super-Resolution
Modern single image super-resolution (SISR) system based on convolutional neural networks (CNNs) achieves fancy performance while requires huge computational costs. The problem on feature redundancy is well studied in visual recognition task, but rarely di
arxiv.org
1. Motivation
1) Heavy single image super-resolution (SISR) models
- FLOPs for processing a single 224×224 image
×2 EDSR: 2270.9G / ResNet50: 4.1G
2) Previous lightweight SISR still use CONV which has feature redundancy
- Previous lightweight SISR
- IDN link: knowledge distillation
- ESRN link: NAS
- PAN link: pixel attention scheme
- Feature redundancy in deep CNN
- SISR need to preserve overall texture and color -> similar features

4) GhostNet is still slow!
- GhostNet link: generating ghost features using depth-wise CONV
- the latency with 256 × 256 input image on a single GPU V100 platform
CONV with 64 output channels: 0.15ms
32-channel CONV + 32-channel depth-wise CONV: 0.19ms
2. Method
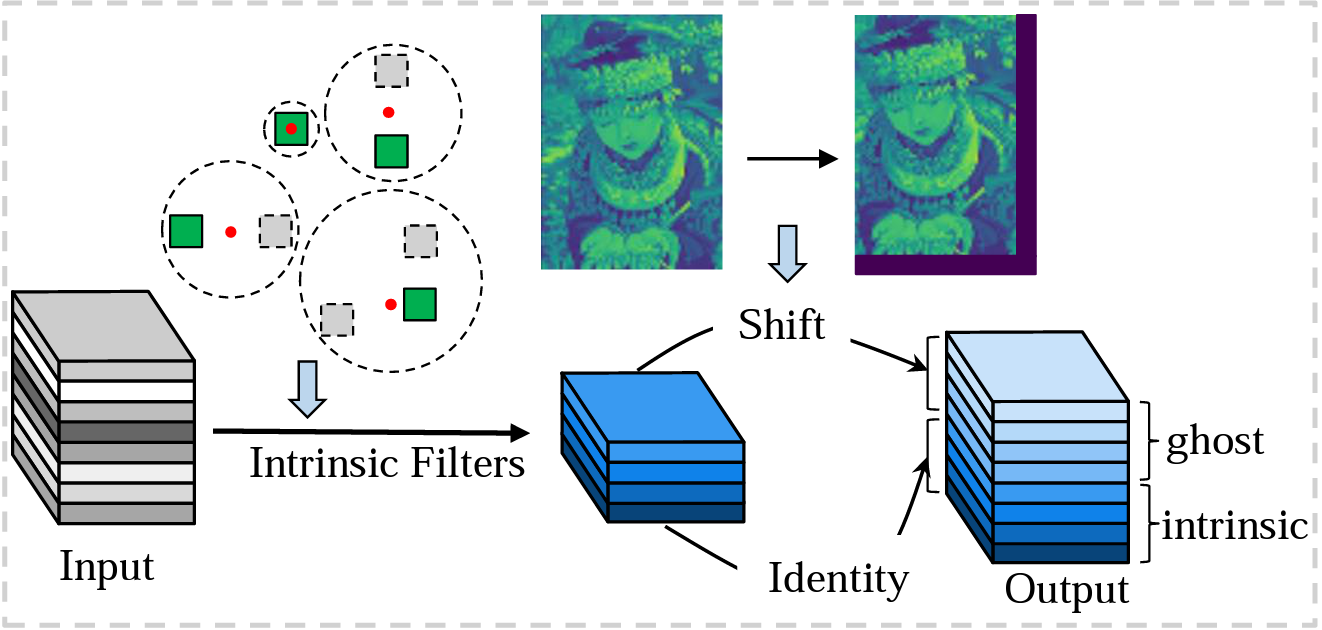
1) Generating ghost features using shift operation (FLOPs-free)
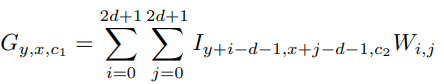
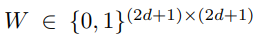

- benefits of shift operation
- high-frequency features, texture info

- larger receptive field

- more efficient, faster
- learnable shift
- trainable W
- Gumbel-Softmax trick
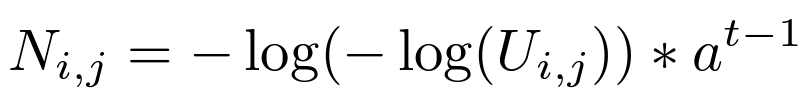




2) Clustering to find intrinsic features (when given pre-trained model)
- vectorize filters from [c_o, c_i , s, s] to [c_o, c_i × s × s]
- apply clustering (k-means)
- select filters which are closest to each center (if a cluster with only one -> select that as intrinsic) -> 흠..

- when clustering adjacent layers, we use previous indices to screen out the useful channel of filters -> clustering again -> repeat...

- if from scratch, c1, c2 set by order
3) Algorithm

3. Experiments & Results
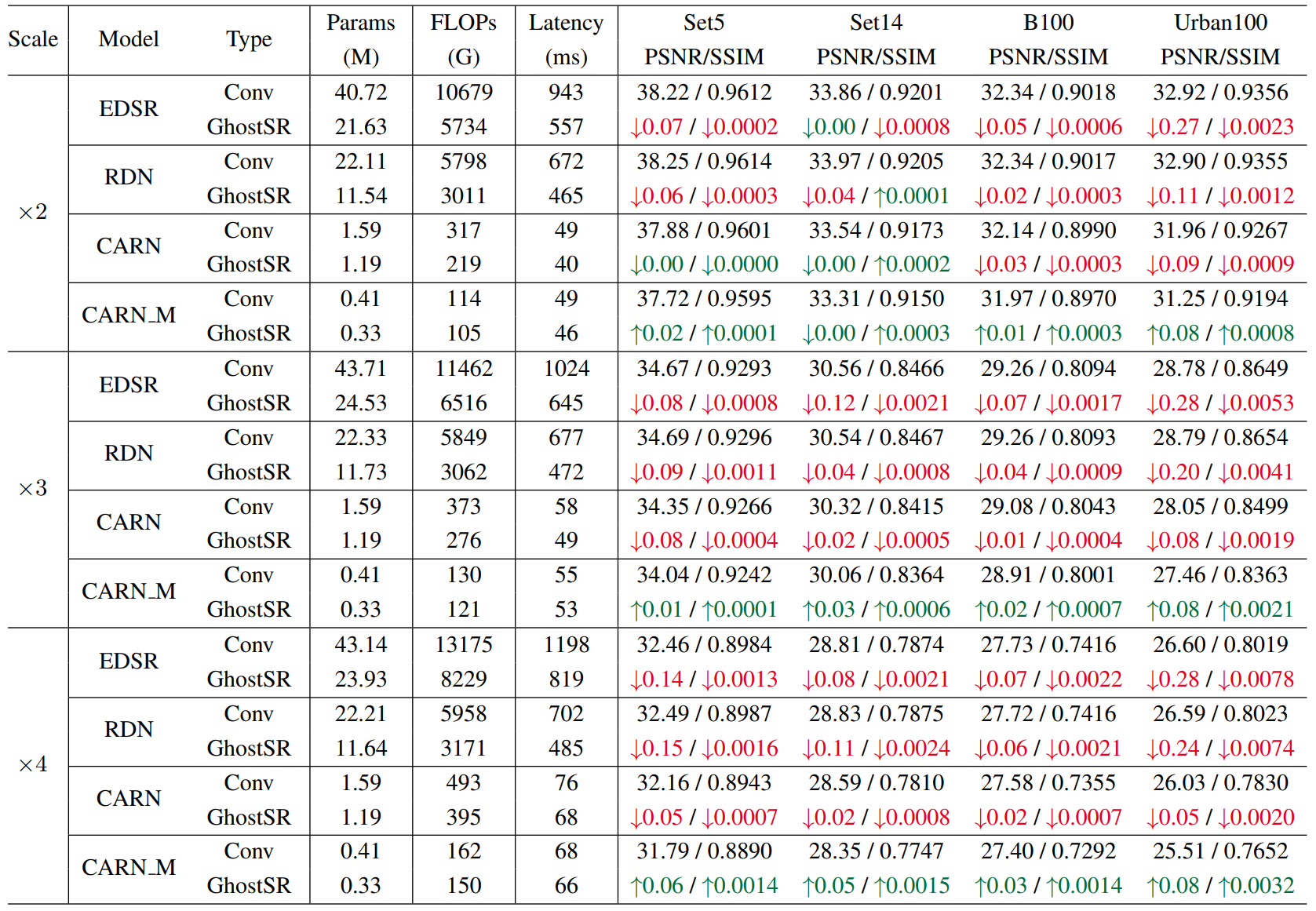
- EDSR x2: Params, FLOPS, Latency 1/2 without performance degradation
- CARN_M: performance increased

- similar results with regular CONV
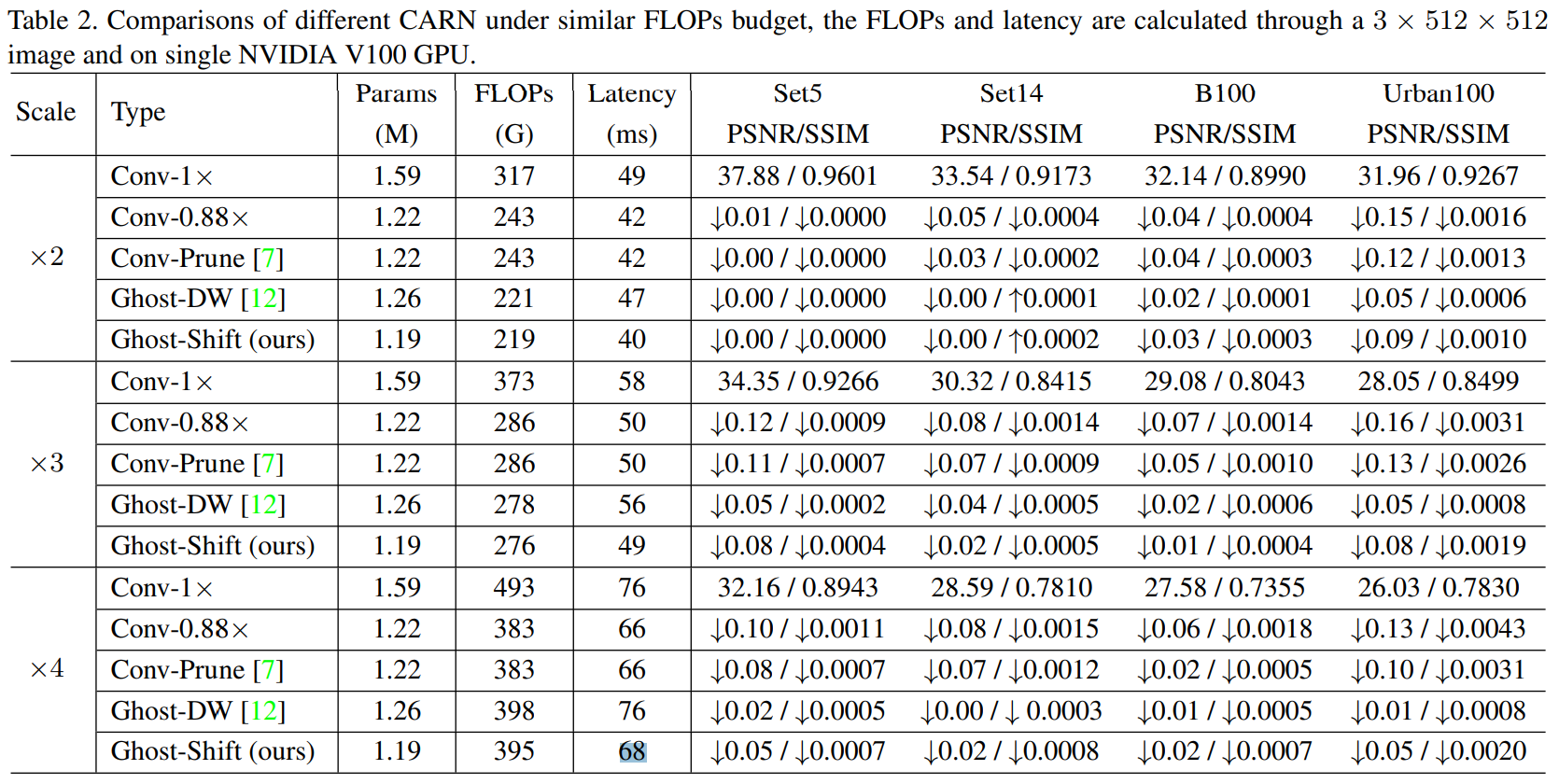
- simply reducing width -> performance degradation
- shift -> DW: performance slightly increased but latency largely increased


- no learnable shift = simply copy
- no pre-trained = trained from scratch

4. etc.
'가슴으로 이해하는 > 경량화, Quantization' 카테고리의 다른 글
| 딥러닝 모델 Quantization이란 (0) | 2021.09.08 |
|---|---|
| [논문 리뷰] Once-for-all: Train One Network and Specialize It for Efficient Deployment (2) | 2021.09.07 |

